MySQL MCP Server
Giving Claude direct access to MySQL through the Model Context Protocol.
MySQL MCP Server
Giving Claude direct access to MySQL through MCP.
I wrote a whole essay a few days ago about why handing AI a connection string to a production database is a career-defining mistake. You can read that one here. If the short version is "don't do the obvious thing," then this post is the longer version of "so what does the non-obvious thing actually look like when you build it?"
I wanted to find out. So I built it.
Is giving AI access to a database okay?
The honest answer is "it depends on what you mean by access."
If you mean pointing Claude at mysql://user:password@host:3306/prod and letting it decide what to ask, then no. That's not access. That's abdication. That's the scenario every engineer who has ever run GRANT ALL on the wrong schema at 2am knows in their bones to be wrong.
But if you mean giving Claude a narrow, observable, revocable channel into a specific slice of data that a human has already approved for AI consumption, that is a different question. That question is actually interesting. And the answer to it lives in the architecture.
So the thesis I started with was this: the database itself should not know Claude exists. Claude should talk to a server. The server should talk to an API. The API should talk to the database. Every layer should be suspicious of the one above it. And the database should be configured as if Claude might, at any moment, try to do the wrong thing.
Architecture
The shape of it looks like this.
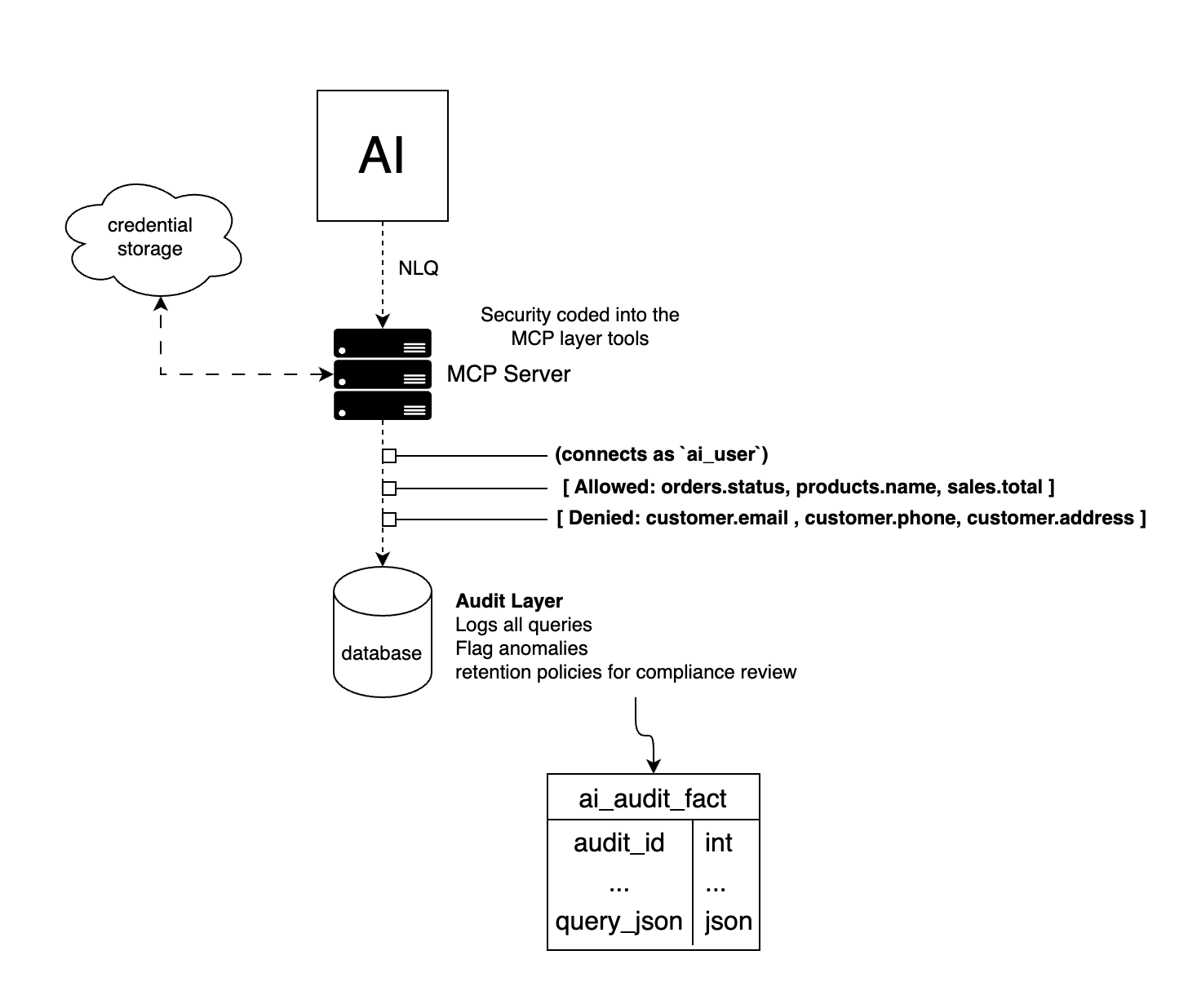
Three tiers. The MCP server speaks the Model Context Protocol to Claude over stdio. It holds no credentials of its own. When Claude calls a tool, the MCP server turns that call into an HTTP request to a FastAPI service running locally. The FastAPI service is the only thing that knows how to reach MySQL. It's also the only thing enforcing the rules.
Why split it? Because the moment you let the MCP server touch the database directly, you have fused the "what Claude is asking for" layer with the "what the database is allowed to answer" layer. When those two things share a process, the rules become conventions. And conventions are what you have right before you have an incident.
Keeping the API separate means the security filter, the parameter binding, the whitelist of allowed statement types, all of it lives in one place, reviewable in isolation, testable without a model in the loop. If Claude goes quiet tomorrow and something else wants to ask the database a question through the same protocol, the security posture doesn't change. The API doesn't care who is calling.
The credentials layer is its own concern. I built a CredentialFactory that resolves secrets from whichever provider the environment is configured for. Locally that's an .env-style resolver. In the cloud that can be AWS Secrets Manager, Azure Key Vault, GCP Secret Manager, or Cloudflare. The database class never sees a raw password. It asks the factory and gets back a dict.
factory = CredentialFactory(provider=self.provider)
secrets = factory.getSecrets()
self.host = secrets.get('host', "")
self.port = secrets.get('port', 3306)
self.user = secrets.get('user', "")
self.password = secrets.get('password', None)
Small thing. But it means the path from "here is a connection" to "here is a hardcoded credential in a config file" is never one step away. You have to go out of your way to do the wrong thing.
The security filter that is actually the whole point
The most important piece of this whole server is about fifteen lines of Python. Every SELECT query that comes through the API gets rewritten on its way to MySQL. If the query has no WHERE clause, one gets added. If it already has one, the filter gets joined in with AND. The filter is approved = 1.
# Case 1: Query has WHERE clause, inject as AND condition
if "WHERE" in query_upper:
where_match = re.search(r'\bWHERE\b', query, re.IGNORECASE)
if where_match:
where_pos = where_match.end()
return f'{query[:where_pos]} {security_filter} AND ({query[where_pos:].strip()})'
That approved column is not a feature of MySQL. It's a convention I enforce in the schema. Every table that the AI can read has an approved flag on every row. A human sets that flag. The MCP server can never flip it. The API physically refuses to run an UPDATE against any table other than sessions.
This is what "human in the loop" looks like when you actually mean it. Not a confirmation dialog. Not a popup asking "are you sure?" A column. Rows the human approved are visible. Rows the human has not looked at do not exist, as far as Claude is concerned.
The INSERT and UPDATE statements that Claude is allowed to issue at all are scoped to one table: sessions. That table is Claude's working memory, a journal of what a given conversation was about. Claude can write its own summaries there. It cannot touch anything else. If Claude's session summary is wrong, the blast radius is a text field.
Demonstrations
With the server running, the surface Claude sees is six tools. Four of them are read operations. Two of them are session-memory operations.
The read side looks like this in practice.
Me: What tables are in the database?>
Claude: I'll check. Calling list_tables...
>
Here are the tables in ai_approved:
- sales — 1,523 rows
- products — 173 rows
- sessions — 42 rows
Me: Show me the schema of sales, then pull the total units sold for December.>
Claude: Calling>describe_tableforsales, thenquery_database.
December 2025 total: 4,218 units across 312 approved rows.
Two things happened in that second exchange that are easy to miss. Claude wrote a SQL query. The API accepted it, rewrote it with approved = 1 injected, ran it against MySQL, and sent the results back. The query Claude thought it was running, and the query MySQL actually ran, are not the same query. That's deliberate. Claude never needs to know about the filter. The filter is not Claude's responsibility.
The session tools are a different story. After a long back-and-forth about schema design, I can say:
Me: Save this session. Summarize what we just worked through and tag it.>
Claude: Calling save_session with the summary and tags...
Now there is a row in sessions with approved = 0. I can review it later. If it's a useful record of what we did, I flip it to approved = 1 and future Claude sessions can find it when they query prior context. If it's junk, I leave it at zero and it stays invisible. The AI proposed. A human disposed.
Powerful, but dangerous
Here is the part where I want to be direct about the failure modes this architecture does not solve.
It does not stop a user from approving a row they should not have approved. If the human in the loop is rubber-stamping sessions without reading them, the approved flag becomes decorative. The control is only as strong as the discipline behind it.
It does not stop a sufficiently motivated prompt from generating a query that does unexpected things inside the approved data. If your approved rows still contain something sensitive, the AI can still reason over it. Scoping the what to approved rows does not automatically scope the how of what can be inferred from them.
It does not stop the LLM provider from seeing the query results during inference. The approved data still leaves your perimeter the moment it enters Claude's context window. If that matters for your compliance posture, and it often does, then the approval boundary needs to be drawn tighter than "is this row okay for analytics." It needs to be drawn at "is this row okay for an external model to see." Those are not the same question.
Every one of those failure modes is solvable. None of them are solved by the server itself. They are solved by the governance around the server. That was the whole point of the earlier post. The protocol is the easy part.
Findings
A few things surprised me while building this.
The boring layer is the most important layer. The regex that injects approved = 1 is the smallest file in the repo and does the most work. The fancy pieces, the async pool, the credential factory, the pydantic models, are all conveniences. The security filter is the actual product.
Splitting the MCP server from the API felt like over-engineering until it wasn't. The first version I prototyped had the MCP server talking to SQLAlchemy directly. Within a day I was leaking concerns across that boundary. Pulling the FastAPI service out between them forced a clean interface and made the security story legible. It also gave me an HTTP surface I could hit with curl during development, which turned out to matter more than I expected.
Claude is well-behaved inside the constraints. When the tool surface is narrow and the errors are clear, the model stays inside the lines. Most of my debugging was about my own code, not about anything the model did. That's a useful thing to know. It means the failure mode I was most worried about, Claude trying to do something clever, is less scary than the failure mode I was least worried about, me shipping a buggy filter.
The session memory tool is quietly the best part. Having Claude write its own conversation summaries into a reviewed table means I get a searchable, curated record of what I worked on and why. It's not the headline feature. It's the one I use most.
What I learned, a lot
I set out to build a narrow MCP server and ended up learning something about governance.
Every decision in this project that felt like friction in the moment turned out to be a boundary that was doing real work. The separate API layer. The approval column. The whitelist of statement types. The credential factory that refuses to hand out a raw password. None of those were strictly necessary to make Claude answer a SQL question. All of them were necessary to make the answer trustworthy.
There is a version of this where I rip all of that out and hand Claude a connection string. It would be faster. The demo would look identical. And the only difference between the two versions is the one that isn't visible in the demo, which is what happens when something goes wrong.
The MCP protocol itself is a fine piece of engineering. It's a clean way to let a model reach into a system that wasn't built for it. What the protocol cannot do, and what the ecosystem has been strangely reluctant to admit, is decide for you what the model should and should not reach. That part is not a technical question. It's an organizational one. It lives in schema design, in access policy, in who gets to flip the approved flag, and in whether anyone is watching the audit trail after the integration goes live.
I wrote this server for myself. But the architecture is the architecture. If you are standing up something like this in a setting where other people's data is involved, the stakes are not that your prototype might embarrass you. The stakes are that a shortcut taken now becomes a disclosure email later.
Take the long path. It's not actually that long.
The repo is on my GitHub if you want to read the code. The regex is in src/api/api.py. The factory is in src/security/credentials.py. Everything else is downstream of those two files.