AI Access into Databases
The MCP Layer - Why your database needs a protocol. Not a password.
AI Access into Databases
The MCP Layer: Why your database needs a protocol. Not a password.
Giving AI unrestrained access to a production database is the biggest red flag of your career.
There. That's the thesis. And if that sentence made you uncomfortable, it's either because you already know it's true, or because someone above you just approved exactly that.
You have seen this meeting
Picture it. A stakeholder, a manager, maybe a CTO, walks into a room with genuine excitement. They just saw a demo. The AI answered questions about sales data in plain English. It pulled trends, surfaced anomalies, summarized the quarter. It was impressive. It looked like magic.
And somewhere in that demo, behind the scenes, the AI had a direct connection string to a production database. Full read access. Maybe more. Nobody in that meeting asked about it. The engineer in the room noticed, said nothing, and felt something sink in their chest.
That engineer is probably reading this right now.
The meeting ends. The integration gets greenlit. The engineer goes back to their desk and starts Googling "how to audit database queries from MCP server."
This isn't a hypothetical. This is a Tuesday at companies across the industry. And the normalization of it is the problem.
What actually just happened in that demo
When an AI agent connects to your database, something has to broker that connection. In the current landscape, that's often an MCP server. For those that don't know, MCP is a specific tool that lets AI models interact with tools and data sources in a structured way. On paper, it's a reasonable architectural idea. A protocol layer sitting between the model and your data.
The problem isn't MCP. MCP is a genuinely sound architectural idea. The problem is how it gets implemented when nobody is asking hard questions.
The naive path is far more common than anyone wants to admit. At a high level, looks like this...
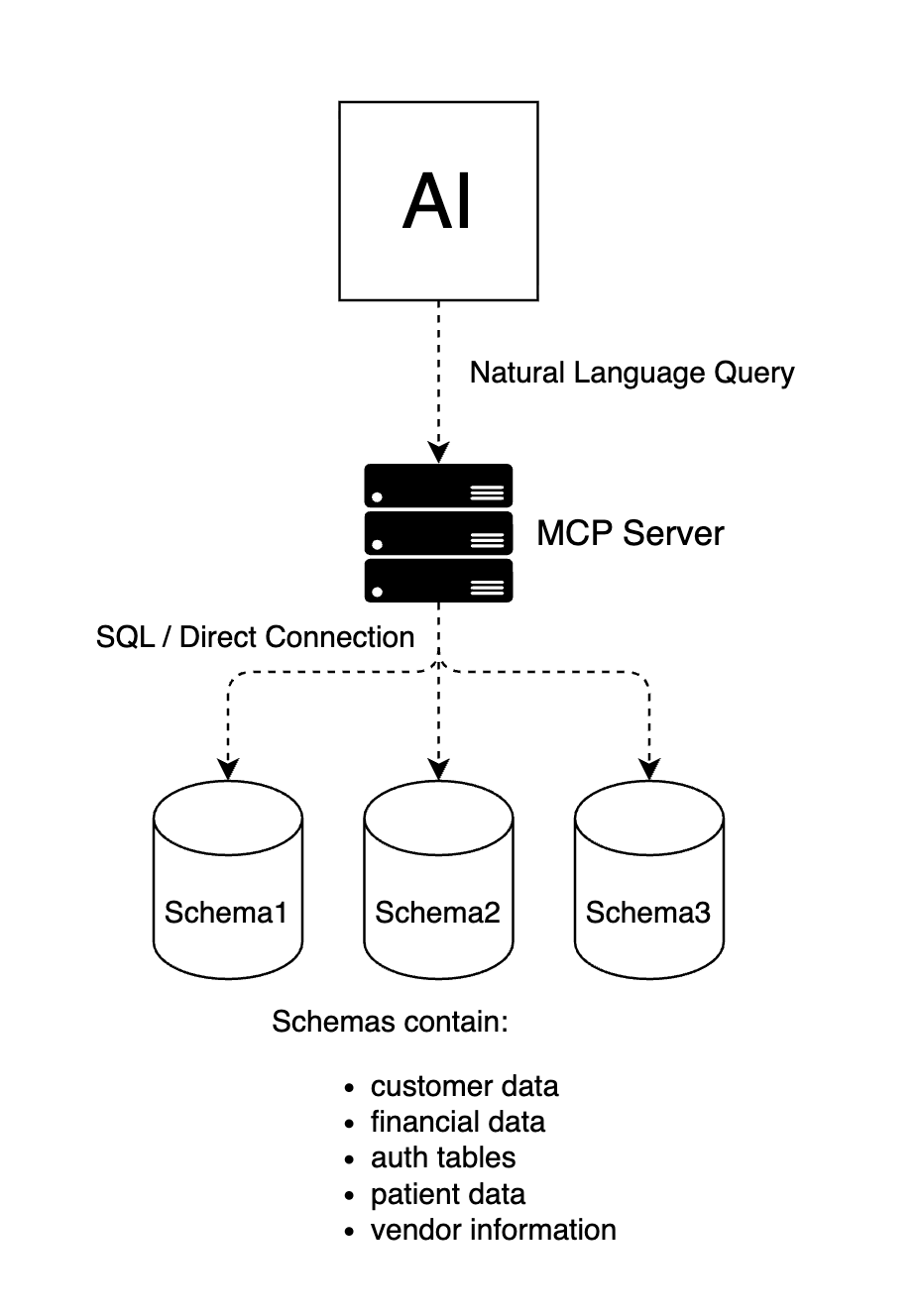
That MCP server is holding credentials. Real ones. And those credentials have access to things the AI has absolutely no business seeing. Not because the AI is malicious. Because nobody scoped it down.
The slightly-less-naive path that still gets it wrong looks like this: someone creates a dedicated database user for the AI. They feel good about that. The user exists. It has a name like ai_readonly or vendor_ai. They hand it broad read access to the entire database and call it a day.
They used a protocol. They still handed it a password with no meaningful boundaries.
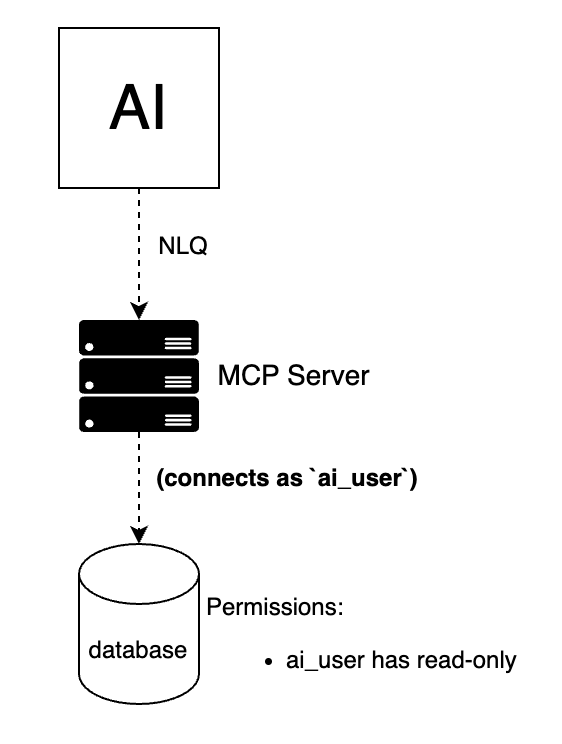
But even this. Guess what. PII? Readable. Financial data? Readable. Auth tokens? Readable. And if your database has performance or information schemas, user host IPs are readable too. Database security settings? Readable. See the pattern?
This isn't security. This is security theater with a friendlier username.
Why the industry keeps getting this wrong
Here is the uncomfortable truth: AI vendors have made it very easy to get something working, and moderately difficult to get something safe. The path of least resistance in most MCP tutorials ends with a connection string and a permissive user. The demos look clean. The GitHub repos have clean READMEs. Nobody puts a warning label on the "getting started" section that says "by the way, this config would be catastrophic in production."
And leadership, to be direct about it, is often making authorization decisions without understanding what they are authorizing. When a manager approves an "AI database integration," they are picturing the demo. They are not picturing the credential scope. They are not thinking about what happens when someone asks the AI a question that happens to touch a table full of customer emails and credit card metadata. They approved a feature. Their engineers inherited a liability.
This isn't a technology failure. it's a governance failure that technology is enabling.
What "done responsibly" actually requires
This isn't a tutorial. But it's worth being direct about what the architectural conversation needs to include before any AI gets near a production database.
The question isn't "did we use MCP?" The question is "what can this AI actually see, and why?"
A responsible architecture forces that question at every layer. What tables does the AI user have access to? Not the database, the specific tables. What columns? Because a customers table might be fine for order data and catastrophically wrong for the column sitting right next to it. Is there an audit trail? Not just connection logs, but what was queried, when, and by which session. If something goes wrong, can you reconstruct what the AI saw?
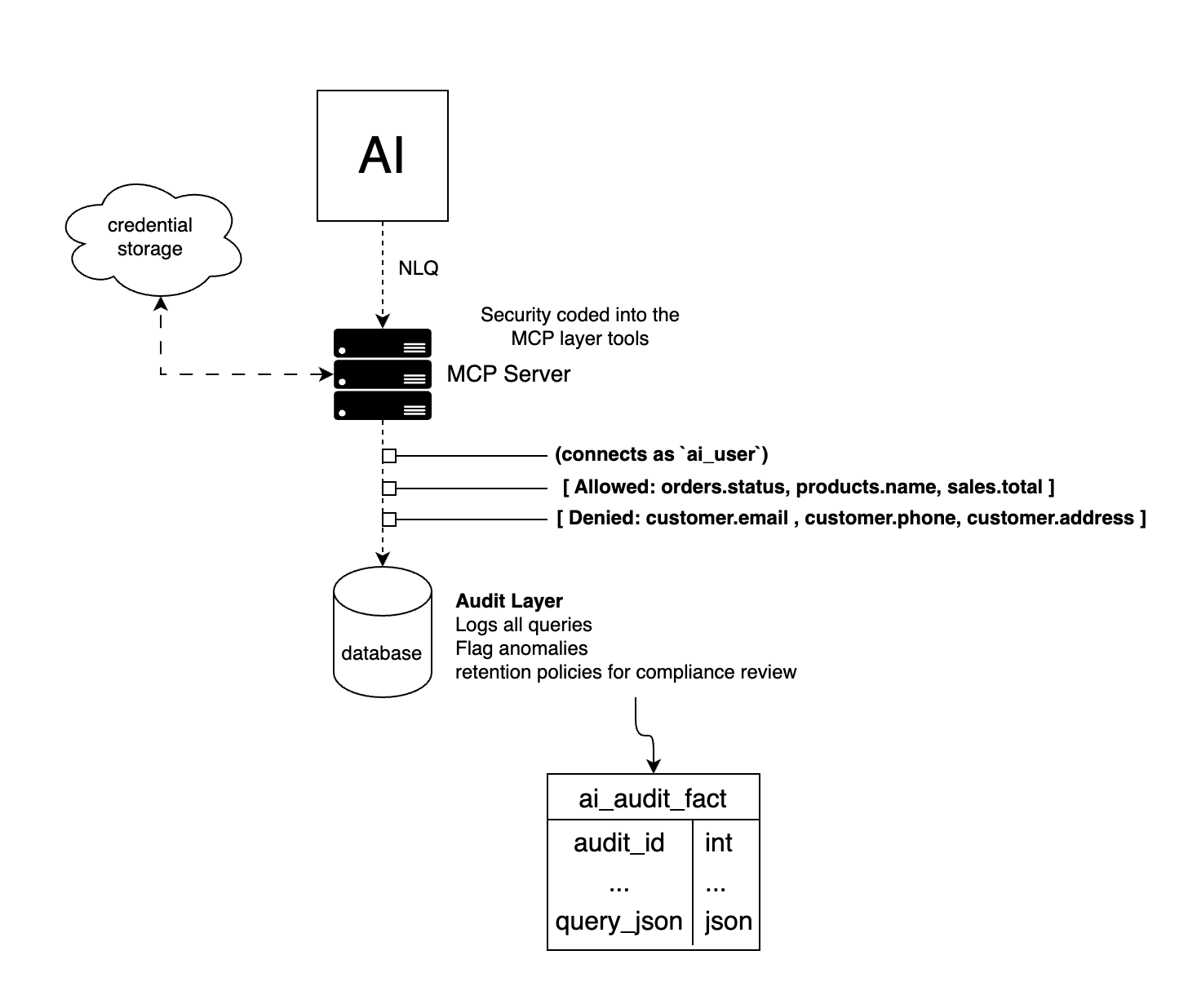
And even that's only responsible if someone owns it. Someone whose job it's to review that audit layer. Someone who gets alerted when the query patterns change. Someone who has the authority to revoke access without a stakeholder meeting to approve it.
Most organizations don't have that person. Most organizations don't have that process. And that's exactly why the default stance toward AI database access should be skepticism, not enthusiasm.
The maturity bar is higher than you think
There is a version of this conversation where the argument is "AI database access is risky now, but once the tooling matures and governance catches up, it will be fine." That's a comfortable take. It lets everyone off the hook and defers the hard work to some future state.
The harder take, and the honest one, is that governance doesn't mature on its own. It matures when organizations decide it's a priority, build the processes, staff the function, and hold the line even when it slows things down. Most organizations are not doing that. They are moving fast, approving integrations in meetings, and trusting that the engineering team will figure out the safety details later.
Later never comes. The integration ships. The access stays broad. The audit trail is either shallow or nonexistent. And the engineer who raised the concern in that original meeting is still the only person who knows where the bodies are buried.
What engineers can actually do
If you are the engineer in that meeting, you already know the risk. The question is what you do with it.
Document everything. If an AI integration gets approved over your objection, or without your input, write down the scope of access, the credentials used, and the date it went live. Not for drama. For the audit trail that did not exist before you created it.
Advocate for the minimum. Even if you cannot stop the integration, you can advocate for the most restricted version of it. A user scoped to specific tables is better than a user scoped to the schema. A user scoped to non-PII tables is better than one that can see everything. Every reduction in scope is a reduction in blast radius.
Make the invisible visible. Most stakeholders don't know what "broad read access" means in practice. If you can show them, concretely, what data the AI can currently reach, that conversation changes. Not always. But sometimes. And sometimes is worth having.
The question worth asking before every integration
Before any AI touches a production database, someone should be able to answer this question clearly: if this AI session were compromised or behaved unexpectedly, what is the worst thing it could expose?
If the answer is "I am not sure," the integration isn't ready.
If the answer requires more than thirty seconds to figure out, the integration isn't ready.
And if nobody in the room thinks that question needs to be asked at all, the organization isn't ready.
The technology exists to do this safely. The protocols exist. The tooling is there. What is missing, in most places, is the organizational will to slow down long enough to use them correctly.
That isn't a technology problem. That's an organizational problem.